Dify連載2回目の記事です。前回に引き続き、つきみがお送りいたします。
さて、前回ではDifyの初期設定とLLMのセットアップをしましたので、次はDifyを使い、簡単にAIを搭載したサービスを作っていきます。
そもそもDifyで何ができるのか?
Difyは高度なプログラミングスキルや、応用的な数学の知識をあまり必要としないで、AIを使って自分好みにカスタマイズすることができます。
例えば、次のものを作ることができます。
- チャットボット
- テキストジェネレーター
- エージェント
- ワークフロー
チャットボットを作ってみる
今回は、「弊社の従業員を紹介するチャットボット」を作っていきます。
管理画面に移って作業を進めていきましょう。
デフォルト設定の場合は、
http://127.0.0.1/にアクセスすることで、スタジオの画面が表示されます。Difyの初期設定とログインが終わっていない方は実施ください。
スタジオの画面が開かれたら、左上の「最初から作成」を選択し、「チャットボット>基本」を選択した上で、各種項目を入力していきましょう。
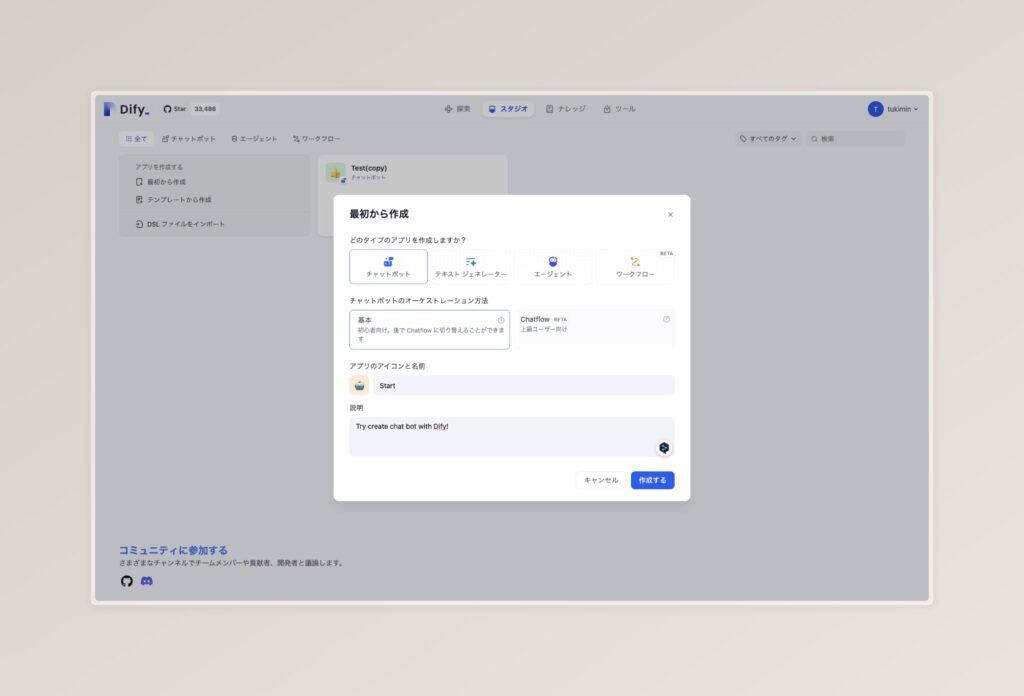
入力内容が決まったら、「作成する」をクリックして、進みます。
前回、デフォルトで使用されるLLM(AIモデル)を設定しました。そのため、右上に「GPT-4o」などと表示されていると思います。表示されていたら適切に初期設定が完了しています。
ただ単純に、「何もカスタマイズしなくていいから、ChatGPTを導入したい」という場合はすでにこの時点で設定が完成しています。試しに右半分の画面の「デバッグとプレビュー」の下にあるテキストボックスになにか打ち込んでみましょう。すると、質問に合わせた回答がされます。
ただ、弊社ではよりAIを活用するために、内部情報と組み合わせてチャットボットの開発を行っています。今回作成するものは「従業員の紹介をするチャットボット」です。
そこで、登場するのが 「RAG」 という技術です。
RAG とは?
RAG(ラグ、Retrieval-Augmented Generation) は、一般的に次のような意味を持っています。
Retrieval-Augmented Generation (RAG) は、大規模言語モデル(LLM)によるテキスト生成に、外部情報の検索を組み合わせることで、回答精度を向上させる技術のこと。
「検索拡張生成」、「取得拡張生成」などと訳されます。外部情報の検索を組み合わせることで、大規模言語モデル(LLM)の出力結果を簡単に最新の情報に更新できるようになる効果や、出力結果の根拠が明確になり、事実に基づかない情報を生成する現象(ハルシネーション)を抑制する効果などが期待されています。
野村総合研究所 用語解説 より – 2024/06/18 閲覧
(読み:ラグ)
つまり、「この事柄は、こういう意味だよ」というネットに転がっていない情報を人間がAI(LLM)に対して与えることによって、より専門的な知識に対して憶測ではなく、できるだけ事実に基づいて回答させるというのが、RAGの役割です。
例えば、「miracleaveの経費精算ってどうするの?」という質問に対して、パブリックな情報しか知らない「GPT-4o」は正確には回答できません。これは、GPT-4oがmiracleaveの内部情報や経費精算に関するプライベートな情報を持ち合わせていないためです。
人が事前に経費精算に関する情報を用意し、GPT-4oがそれらの情報を取り扱えるようになれば、プライベートな問題でもなるべく正確に答えてくれるようになるということです。
RAGに使用するデータを用意する
では、RAGで使用するデータを用意しましょう。
今回の場合簡単に自己紹介の情報を集めたいと思うので、弊社のテックブログで自己紹介を設定している従業員の皆様の情報をまずは収集しました。
(軽く書いたコードのため乱雑なのと、CSMとESな書き方が混在しているのはご容赦ください…)
従業員一覧の取得部(Node.js)
const fs = require('fs');
(async function () {
async function wait(second) {
return new Promise(resolve => setTimeout(resolve, second));
};
let totalData = []
for (let i = 1; ; i++) {
const data = await (await fetch(`{ブログのURL}/wp-json/wp/v2/users?orderby=id&page=${i}`, {
headers: {
"Authorization": "[ここに認証情報]"
}
})).json()
const returnData = data.filter((data) => {
if (data.description === "") return false
return true
}).map((data) => {
return {
name: data.name,
description: data.description.replace("\r\n", "\n")
}
})
console.log(returnData)
totalData = [...returnData, ...totalData]
await wait(2000)
if (data.lenght !== 10) break;
}
console.log(totalData)
const header = 'name, description\n';
const csvData = totalData.map(item => `${item.name}, ${item.description}`).join('\n');
const csvContent = header + csvData;
fs.writeFile('output.csv', csvContent, 'utf8', (err) => {
if (err) {
console.error('Error writing to file', err);
} else {
console.log('CSV file has been saved.');
}
});
}());このソースコードを実行することによって、次のようなcsvファイルがフォルダーに作成されました。
name, description
miracleave, miracleaveはワクワクする最高のITサービスをユーザーに提供するテクノロジー集団です。 「ITでワクワクできる未来へ」をミッションに掲げ、楽しいを創り出す組織から、お客様に感動を与えるようなサービスを届けること、そして、新たな挑戦をする人をデジタルコンテンツの力で後押し、幸せな未来を作っていきたいと考えています。
木村, ブライダル業界 → 2021年9月 miracleave に転職 未熟者ですが、よろしくお願いいたします! 甘いもの大好きすぎる。。
長田, miracleave初期メンバー。 コロナで機会が激減しましたがライブやフェスに行くのが好きです。
竹村, 2021年2月にmiracleaveにジョインしました。 現在はPythonとDjangoで開発しています。
大友, AWS資格取得に向けて絶賛勉強中!
S.S, ゲーム好きプログラマ。 2021年12月よりmiracleaveに入社しました。次は、作成されたファイルをDifyにアップロードをします。
RAGのために作ったファイルをアップロードする
上のヘッダーから、ナレッジに移動し、左上の「知識を作成」をクリックします。
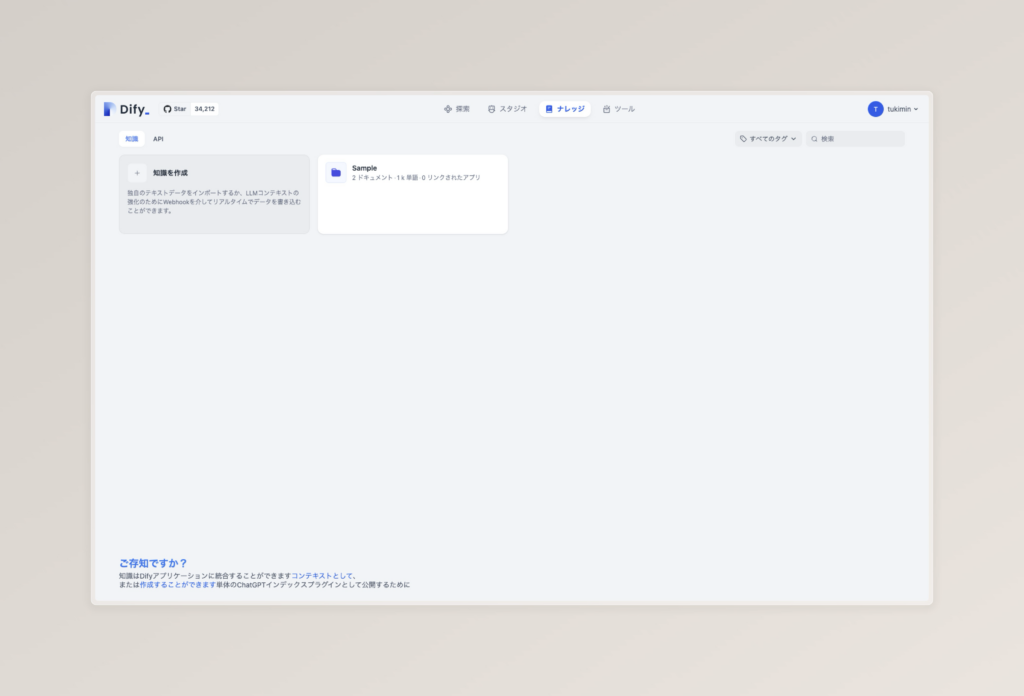
そうしたら、テキストファイルからインポートを選択した状態で、ファイルをアップロードしましょう。
(今回の場合は先ほど作成した、弊社のテックブログのデータをアップロードします)
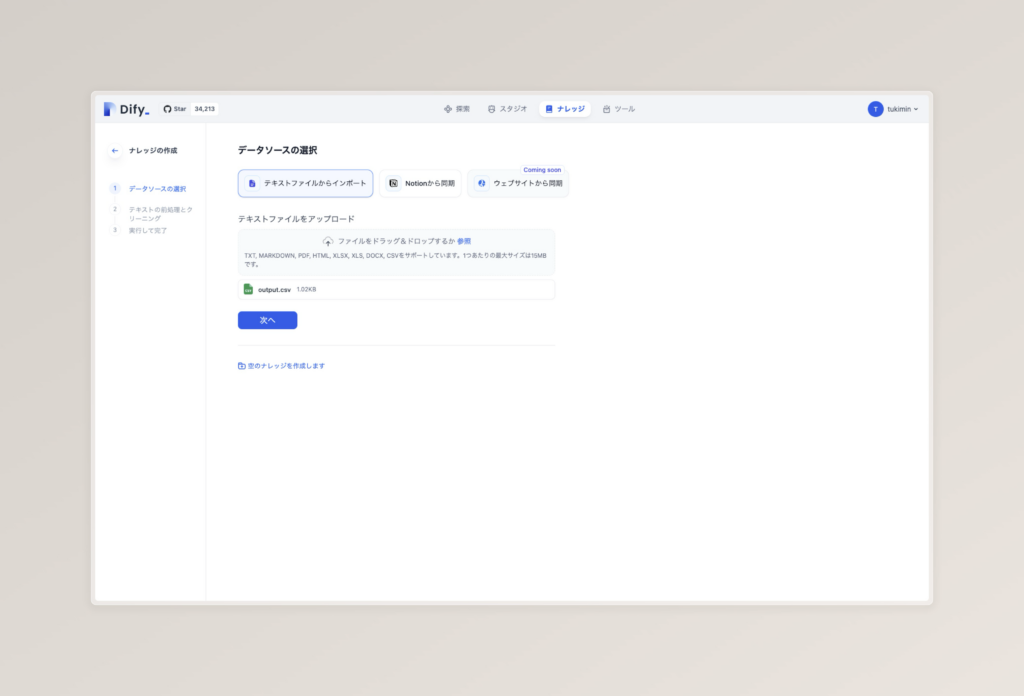
次へを押すと、次のような画面になります。
今回の場合初めての人を想定しているため、デフォルトの選択肢のまま進みます。
(検索設定に再ランクモデルと表示されていますが、これは次回触れます。ぜひお待ちください。)
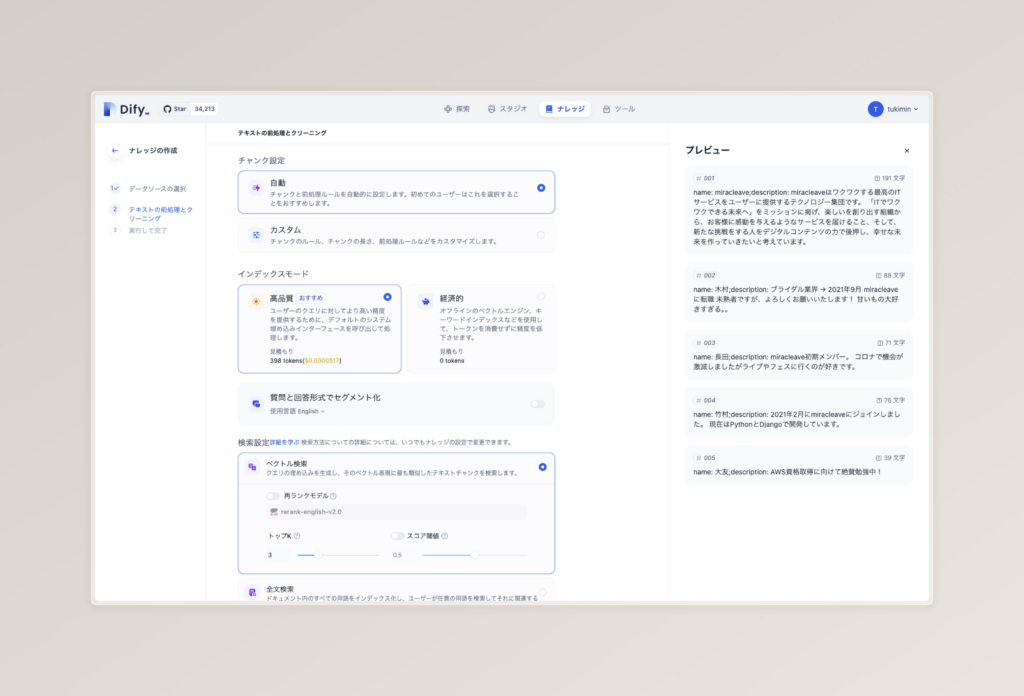
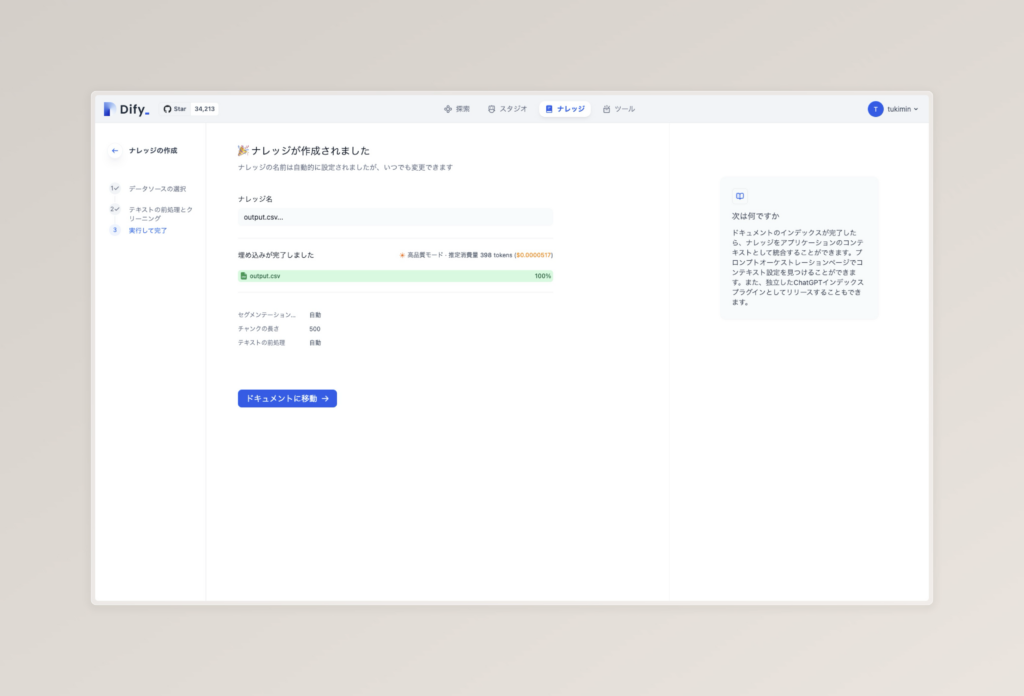
設定を終わらせ、次に進むと以下のような画面になります。
ここまでで、RAGの準備完了です。
動作するか検証しよう
ドキュメントに移動し、左のナビゲーションバーから真ん中の「検索テスト」に移動し、ソーステキストというテキストボックスの右上の設定を「全文検索」にしてみてください。
(オプションとりあえずデフォルトのままで大丈夫です。)
試しに「miracleaveってなに?」と聞いてみましょう。
全文検索の場合
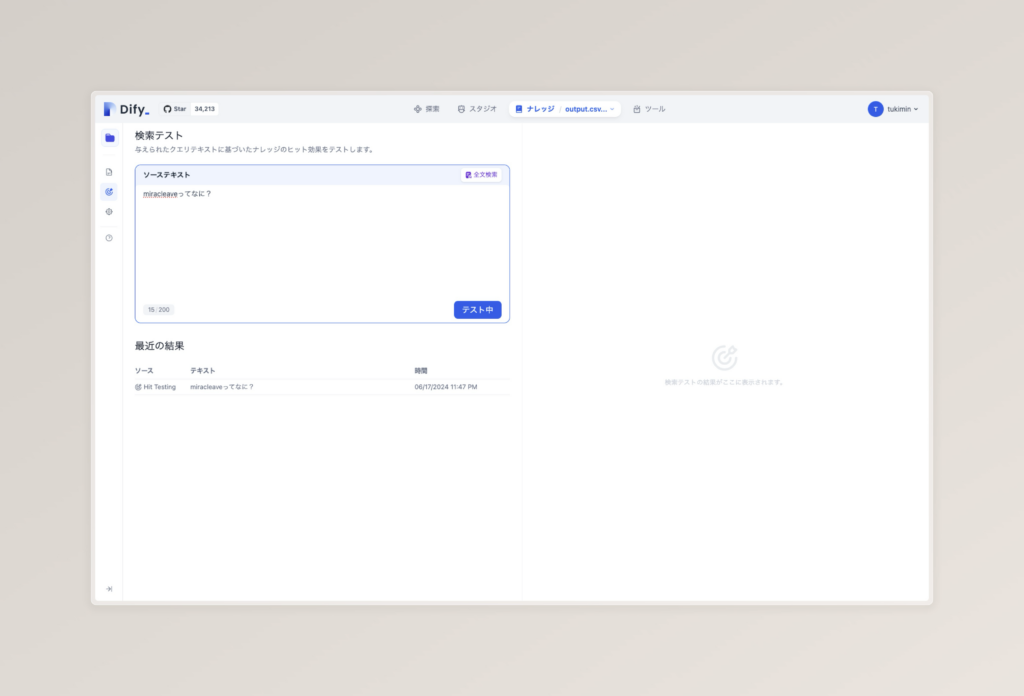
おや?表示されませんでした。
ここでいう、全文検索とは「miracleave」「なに」といった単語単位で一致するものを検索します。今回、この単語に一致する文章が存在しないがために発生します。
試しにもう一つの検索手法である、ベクトル検索を試してみましょう。
ベクトル検索の場合
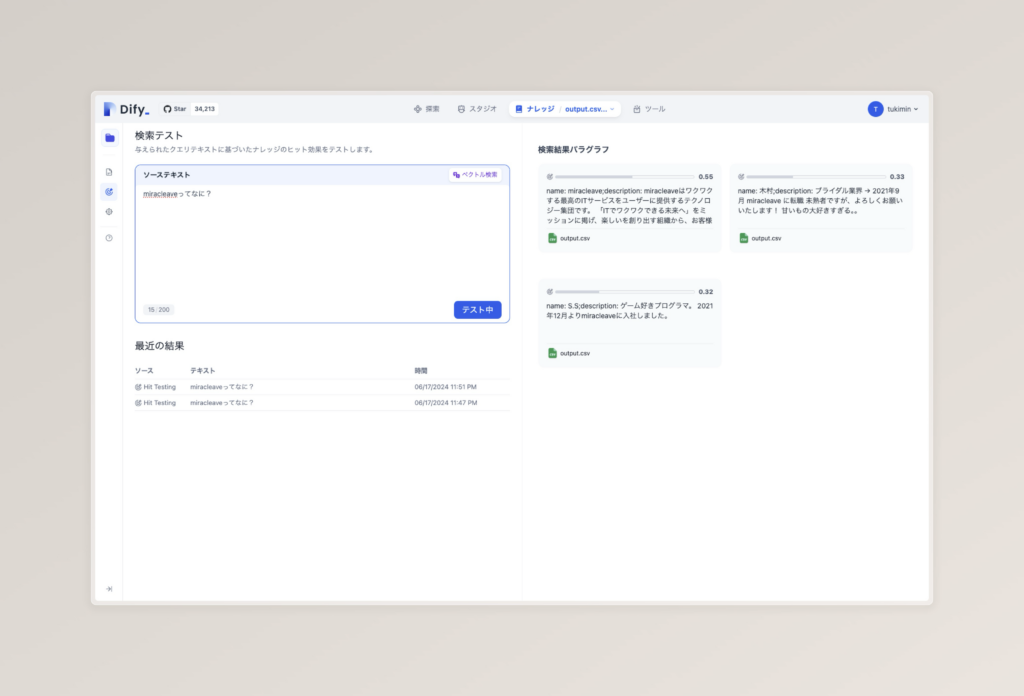
検索結果が表示されましたね。なぜ表示されたのでしょうか?
簡単に言えば私が聞いた文章を、言語モデルがベクトル化(Embedding)してくれます。事前にすべての文字列は言語モデルによってベクトル化が済んでおり、似ているコンテンツは座標上で近いところのベクトルとして保存されています。
私が「miracleaveってなに?」と聞いた場合、この文章をベクトル化し、そのベクトルを元に近いベクトルのデータを探します。検索結果が先ほどの全文検索と違う理由となります。
質問文章を元に近いデータを探る方法は第一回にも軽く触れたコサイン類似度を使いますが、それらの知識がなくても代わりにDifyがやってくれます。非常に便利ですね。
この辺りの仕組みは「ベクトル検索 コサイン類似度」などと検索することでより深い理解を得られます。ぜひ参照してみてください。
チャットボットに組み込む
さて、Difyのスタジオに戻り、先ほど作成したアプリケーションに戻りましょう。
コンテキスト>追加 に進み、作成したナレッジ(今回の場合は output.csv )を選択して追加しましょう。
さて、これで準備は整いました。
続いて、「木村さんってどんな人?」と質問してみましょう。
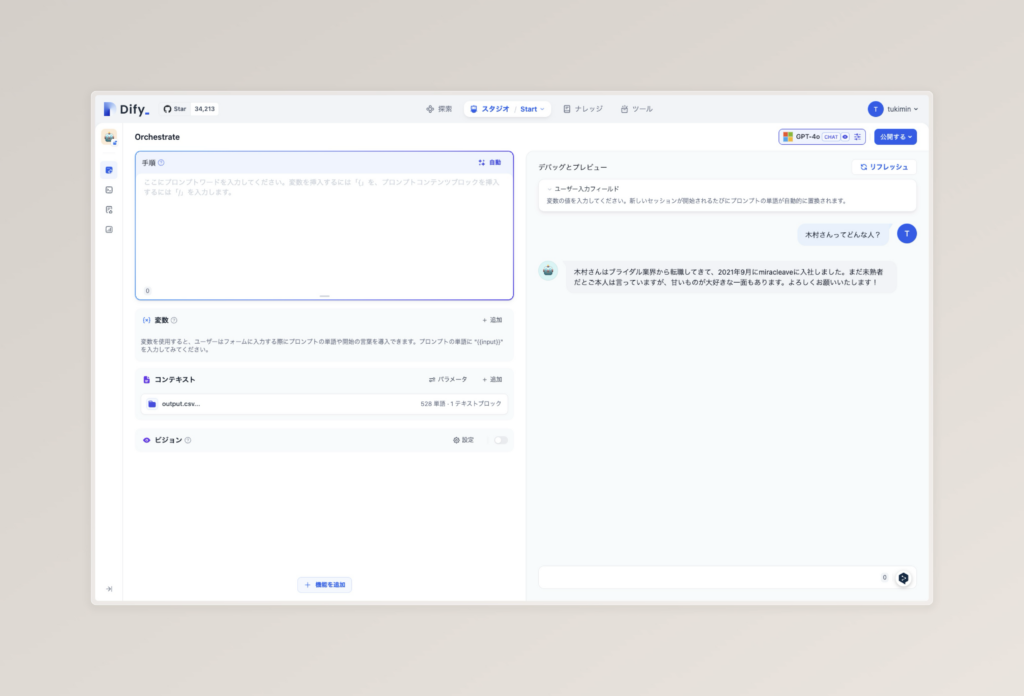
元データ(自己紹介文)
木村, ブライダル業界 → 2021年9月 miracleave に転職 未熟者ですが、よろしくお願いいたします! 甘いもの大好きすぎる。。
AIの返信(元データを元に返信した場合)
木村さんはブライダル業界から転職してきて、2021年9月にmiracleaveに入社しました。まだ未熟者だとご本人は言っていますが、甘いものが大好きな一面もあります。よろしくお願いいたします!
完璧な木村さんの紹介が取り出せました。
まとめ
いかがだったでしょうか?
今回は、Difyを使ったRAGの構築をしてみました。その中で、全文検索やベクトル検索といった事柄を扱いました。皆様の理解の助けになれば幸いです。
番外編
AIの文章は、どこか堅苦しさが見られます。もうちょっと気前のいい、ラフに話しかけられるようなAIを作っていきましょう。
これは、ChatGPTでよく言われる「プロンプトエンジニアリング」の分野に入っていきます。この意味は、プロンプトを日本語でどれだけAIにわかりやすく書くかです。気になる人はインターネットで調べてみてください。
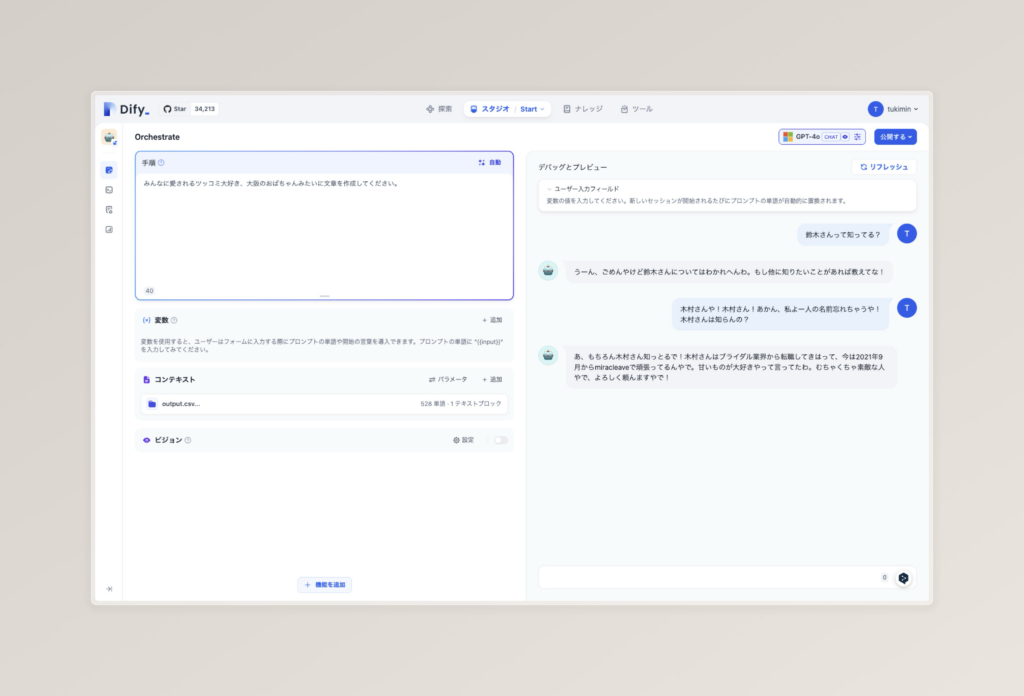
さて、今回は気分で大阪のおばちゃんをAIに演じてもらいます。今回は番外編で深掘りしようとは考えていないので、軽くプロンプトを書きます。
プロンプトは左上のテキストボックスである「手順」から追加します。プロンプトを記載し終わったら、右側のプレビューがリロードを要求してくるため、リロードをしてみましょう。
登録が完了したら、試しに話しかけてみましょう。
今回は事前にデータを登録していない「鈴木さん」と、データが登録されている「木村さん」について聞いてみたところ、いい感じに大阪のおばちゃん風に返してくれました。まるで大阪の人情の温かみを感じます…(私は都民なので実際にこんな優しいおばちゃんが居るのかは不明ですが…)